Perché scegliere un modello di AI locale invece di usare servizi online
Nel precedente articolo Usare la AI in locale con LM Studio: guida pratica per chi tiene davvero alla Privacy abbiamo visto come sia possibile eseguire modelli di intelligenza artificiale direttamente sul proprio computer, senza affidare conversazioni, documenti o dati personali a servizi cloud esterni. È uno degli aspetti che sta rendendo l’AI locale sempre più interessante, privata e sicura anche per gli “utenti comuni”.
Oltre alla privacy, esistono altri vantaggi molto concreti. Un modello eseguito in locale può essere utilizzato anche senza connessione Internet, non richiede abbonamenti mensili e permette una libertà d’uso spesso maggiore rispetto ai servizi online. Chi utilizza l’AI per scrivere testi, fare ricerche, programmare o semplicemente sperimentare può avere un controllo quasi totale sull’ambiente di lavoro.
Un errore molto comune è cercare ed installare il modello AI locale più potente disponibile senza considerare l’hardware realmente presente nel proprio PC. Il risultato è spesso frustrante: tempi di risposta lunghissimi, consumi elevati e prestazioni deludenti.
Lo scopo di questo articolo è quello di dare a tutti la possibilità di provare o utilizzare i modelli locali di Intelligenza Artificiale. Vedremo quali sono i modelli più adatti ad essere installati su PC poco o mediamente performanti, o datati, senza dover rinunciare alle funzionalità e caratteristiche.
Da dove partire
Quando si parla di AI locale spesso ci si chiede: “Qual è il miglior modello da installare? (al di là delle necessità), ma per quanto vedremo in seguito non è la domanda giusta.
Quella corretta è: “Qual è il miglior modello AI locale che il mio computer riesce a eseguire in modo fluido?”
Il compromesso tra qualità e requisiti hardware
Ogni modello di AI locale rappresenta un compromesso tra:
- qualità delle risposte;
- velocità di elaborazione;
- memoria richiesta;
- spazio occupato su disco.
Un modello AI locale da 70 miliardi di parametri può essere straordinario, ma su un PC con 8 GB di RAM risulterà praticamente inutilizzabile.
Al contrario, un modello AI locale da 3 o 4 miliardi di parametri potrebbe offrire risposte più che soddisfacenti per uso quotidiano mantenendo un’esperienza fluida.
Comprendere e valutare i parametri del modello
Quando si leggono nomi come:
- Llama 3 8B
- Gemma 3 4B
- Qwen 3 8B
- Phi 4 Mini
Il nome è ovviamente il nome del modello mentre la sigla finale indica il numero di parametri espressi in Miliardi. (la B sta per Billions, appunto, Miliardi)
Schematicamente:
| Parametri | Utilizzo consigliato |
|---|---|
| 1B – 4B | PC poco potenti |
| 7B – 9B | PC domestici medi |
| 12B – 14B | PC abbastanza performanti |
| 30B+ | Hardware avanzato |
Per la maggior parte degli utenti privati, la fascia tra 4B e 8B è il punto di equilibrio ideale tra performances e risorse.
Come valutare il proprio PC prima di scaricare un modello
Memoria RAM disponibile
La RAM è probabilmente il fattore più importante.
Indicativamente:
| RAM disponibile | Modelli consigliati |
|---|---|
| 4 GB | 1B |
| 8 GB | 2B – 4B |
| 16 GB | 7B – 8B |
| 32 GB | 12B – 14B |
| 64 GB+ | modelli più grandi |
Se il PC dispone di soli 8 GB di RAM è comunque possibile ottenere risultati interessanti utilizzando modelli di AI locale con versioni quantizzate (GGUF) disponibili direttamente tramite LM Studio.
CPU e GPU: cosa conta davvero
Molti credono che sia indispensabile una scheda grafica da gaming di fascia alta, in realtà non è più così e LM Studio consente di eseguire diversi modelli direttamente tramite CPU. Naturalmente una GPU moderna accelera notevolmente le prestazioni, ma non è obbligatoria per iniziare.
Per un utilizzo domestico di AI locale sono spesso sufficienti:
- Intel Core i5 degli ultimi anni;
- AMD Ryzen 5;
- Apple Silicon M1 o superiori.
- Snapdragon
Sistema operativo supportato
LM Studio supporta:
- Windows 10 e Windows 11
- macOS
- Linux
Le principali famiglie di modelli consigliate per PC domestici
Gemma
Sviluppata da Google, la famiglia Gemma si è costruita rapidamente una reputazione eccellente.
Punti di forza:
- buona comprensione del linguaggio;
- velocità elevata;
- requisiti relativamente contenuti.
Versioni consigliate:
- Gemma 3 4B
- Gemma 3 7B
Ottime per scrittura, studio e uso generale.
Qwen
I modelli Qwen di Alibaba stanno ottenendo risultati sorprendenti.
Sono particolarmente apprezzati per:
- ragionamento;
- coding;
- supporto multilingua.
Versioni consigliate:
- Qwen 3 4B
- Qwen 3 8B
Rappresentano probabilmente uno dei migliori compromessi attualmente disponibili.
Phi
La serie Phi di Microsoft nasce proprio con l’obiettivo di offrire prestazioni elevate su hardware limitato.
Versioni consigliate:
- Phi 4 Mini
- Phi 3 Mini
Ideali per:
- notebook economici;
- mini PC;
- computer con poca RAM.
Llama
La famiglia Llama di Meta è probabilmente la più conosciuta.
Punti di forza:
- enorme disponibilità di versioni;
- comunità vastissima;
- ottimo supporto in LM Studio.
Versioni consigliate:
- Llama 3.2 3B
- Llama 3.1 8B
Mistral
Mistral rimane una delle migliori opzioni per chi desidera un assistente versatile.
Versioni consigliate:
- Mistral 7B
- Ministral
Molto equilibrati tra qualità e velocità.
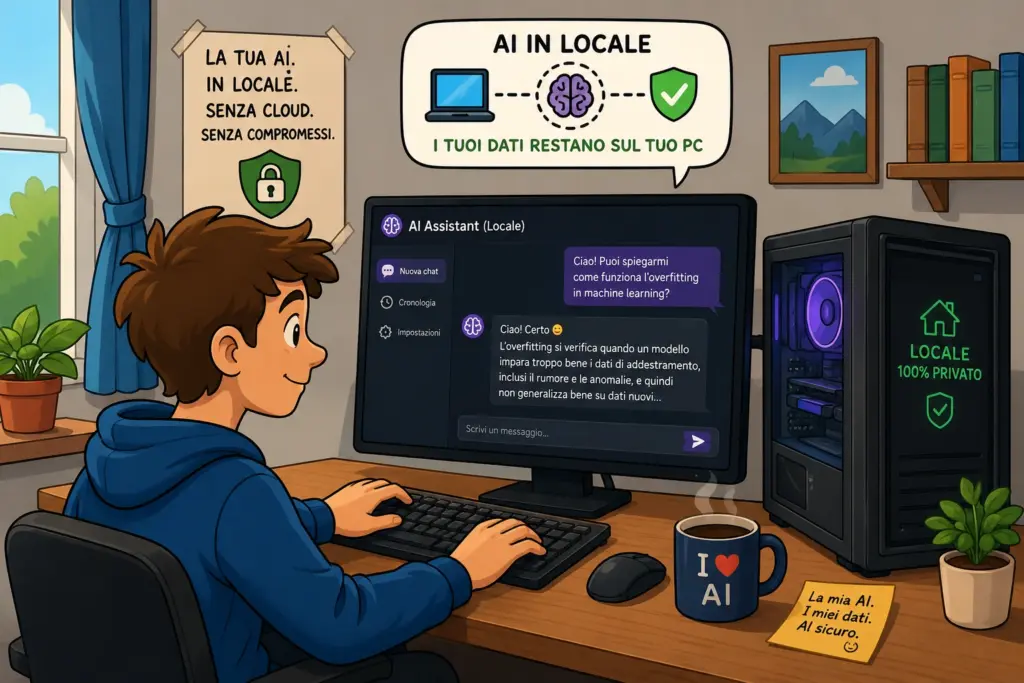
Tabella comparativa dei modelli consigliati
| Modello | Parametri | RAM consigliata | Windows | LM Studio | Utilizzo |
|---|---|---|---|---|---|
| Phi 4 Mini | ~4B | 8 GB | ✔ | ✔ | Uso generale |
| Gemma 3 4B | 4B | 8 GB | ✔ | ✔ | Scrittura e studio |
| Llama 3.2 3B | 3B | 8 GB | ✔ | ✔ | Chat e assistenza |
| Qwen 3 4B | 4B | 8-12 GB | ✔ | ✔ | Multilingua |
| Llama 3.1 8B | 8B | 16 GB | ✔ | ✔ | Uso avanzato |
| Qwen 3 8B | 8B | 16 GB | ✔ | ✔ | Coding e produttività |
| Mistral 7B | 7B | 16 GB | ✔ | ✔ | Assistente generico |
| Gemma 3 12B | 12B | 32 GB | ✔ | ✔ | Utenti esperti |
Quale modello AI locale scegliere in base all’hardware disponibile
PC entry-level (6/8 GB RAM)
Se il computer dispone di 8 GB di RAM è consigliabile orientarsi su:
- Phi 4 Mini
- Gemma 3 4B
- Llama 3.2 3B
- Qwen 3 4B
Sono modelli capaci di offrire una buona esperienza senza mettere in crisi il sistema.
PC medio (16 GB RAM)
I modelli consigliati sono:
- Llama 3.1 8B
- Qwen 3 8B
- Mistral 7B
- Gemma 3 7B
PC “importante” (min 32 GB RAM)
Con 32 GB di RAM si può iniziare a sperimentare modelli di AI locale più complessi senza particolari problemi.
Tra i più interessanti:
- Gemma 3 12B
- Qwen 14B
- Llama 3 14B (versioni compatibili)
Modelli uncensored e modelli NSFW (Not SafeForWork)
Cosa significa uncensored
Un modello uncensored è un modello nel quale molte delle limitazioni imposte dagli sviluppatori sono state ridotte o eliminate.
Può essere utilizzato per:
- roleplay;
- scrittura creativa;
- storytelling avanzato;
- ricerca e sperimentazione.
L’assenza di filtri comporta anche maggiori responsabilità nell’utilizzo.
Tra i nomi più noti:
- Dolphin Llama
- Dolphin Mistral
- OpenHermes
- Nous Hermes
Modelli NSFW disponibili in locale
Esistono anche modelli specificamente addestrati per contenuti destinati a un pubblico adulto.
Questi modelli sono destinati esclusivamente a utenti maggiorenni e devono essere utilizzati nel rispetto delle normative vigenti e delle condizioni di utilizzo dei relativi progetti.
Tra i modelli frequentemente utilizzati dalla comunità locale troviamo:
- Dolphin Uncensored
- Magnum
- Midnight Miqu
- Euryale
- Mythomax
È importante ricordare che questi modelli possono generare contenuti espliciti, simulazioni di roleplay adulto o materiale non adatto ai minori.
Come installare e provare questi modelli con LM Studio
Il processo è estremamente semplice:
- Installare LM Studio dal sito ufficiale.
- Aprire la sezione di ricerca dei modelli.
- Cercare il modello desiderato.
- Preferire versioni GGUF quantizzate (Q4 o Q5).
- Scaricare il modello.
- Caricarlo nella sezione Chat.
- Iniziare la conversazione.
Per la maggior parte degli utenti le versioni Q4_K_M rappresentano il miglior compromesso tra qualità e consumo di memoria.
Errori comuni da evitare
Uno degli errori più frequenti consiste nello scaricare il modello più grande disponibile pensando che sia automaticamente il migliore.
Altri errori comuni includono:
- ignorare la RAM disponibile;
- scaricare modelli non compatibili con il proprio hardware;
- usare versioni non quantizzate;
- aprire troppe applicazioni contemporaneamente;
- sottovalutare lo spazio necessario sul disco.
Spesso un buon modello da 4B o 8B ben ottimizzato offre risultati migliori di un modello enorme che il computer fatica a gestire.
Conclusione
L’intelligenza artificiale locale quindi non è riservata solo a chi possiede workstation professionali o computer da migliaia di euro. Oggi un normale PC domestico può eseguire modelli sorprendentemente validi, soprattutto grazie a strumenti come LM Studio che rendono l’intero processo accessibile anche ai meno esperti.
Per chi desidera muovere i primi passi, Gemma 3 4B, Phi 4 Mini, Qwen 3 4B e Llama 3.2 3B rappresentano ottimi punti di partenza. Chi dispone di 16 GB di RAM può invece orientarsi su Qwen 3 8B, Llama 3.1 8B o Mistral 7B, ottenendo un’esperienza molto vicina a quella dei servizi cloud più diffusi.
La regola più importante rimane una sola: scegliere il modello in base al proprio hardware, non alle classifiche online. Un modello che gira bene sul proprio PC sarà quasi sempre più utile di uno teoricamente superiore ma inutilizzabile nella pratica.
FAQ
1. Posso usare l’AI locale con soli 6/8 GB di RAM?
Sì. Modelli come Phi 4 Mini, Gemma 3 4B e Llama 3.2 3B sono progettati proprio per hardware modesto.
2. Serve una scheda video dedicata?
No. Una GPU aiuta molto, ma molti modelli possono funzionare anche utilizzando esclusivamente la CPU.
3. LM Studio è gratuito?
Sì, LM Studio può essere utilizzato gratuitamente per scaricare ed eseguire modelli locali.
4. Qual è il miglior modello per scrivere testi?
Attualmente Gemma, Qwen e Llama nelle versioni da 7B-8B offrono ottimi risultati per scrittura e produttività.
5. I modelli uncensored sono illegali?
No. Sono modelli privi di molte limitazioni applicate dai produttori, ma il loro utilizzo deve sempre rispettare le leggi e le normative applicabili.
Ultimi Articoli
Recent Post






Disney + 2,74€/mese
Netflix 3,67€/mese
Prime 3 mesi a 4,92€
YouTube Premium 3,92€/mese
Spotify 4,50€/mese
Gemini 3,50€/mese
ChatGPT 5,77€/mese
Perplexity 4,09€/mese
Grok 6,17/mese
Claude 5,49€/mese
Canva 4,99€/mese
Adobe 16,53€/mese
..e molto altro
I prezzi possono subire lievi variazioni